
全文共2343字,阅读时长约为4分钟
图片来源 |网络
先声论:AI正在改变我们的经济和社会,改变我们交流的方式,改变我们的行政和政治。不平等在我们的社会中积疾已久,不能让AI在不经意间延续甚至恶化这一问题了。
本文节选、编译自Nature平台的文章AI can be sexist and racist — it’s time to make it fair,原文作者James Zou &Londa Schiebinger。
谷歌翻译在将西班牙语新闻翻译成英语时,通常将提及女人的句子翻译成“他说”或“他写道”。尼康相机中用来提醒拍照者照片中的人有没有眨眼的软件有时会把亚洲人识别为总在眨眼。
单词嵌入——一个用来处理和分析大量自然语言数据的流行算法,会把欧裔美国人的姓名识别为“正面”词汇,而非裔美国人的姓名识别为“负面”词汇。

△图片来源:iStock/Getty(左图)
Prakash Singh/AFP/Getty(右图)
在有偏差的数据集上训练出的算法通常只能将左边的图片识别为“新娘”。
除此之外,人们还发现了其他很多人工智能(AI)系统性地歧视特定人群的例证。
决策偏见并不是AI独有的问题,但由于AI的应用范围越来越大,解决AI偏见至关重要。
导致AI产生偏见的原因
导致AI产生偏见的一个主要因素是训练数据。大多数机器学习任务都是使用大型、带标注的数据集来训练的。
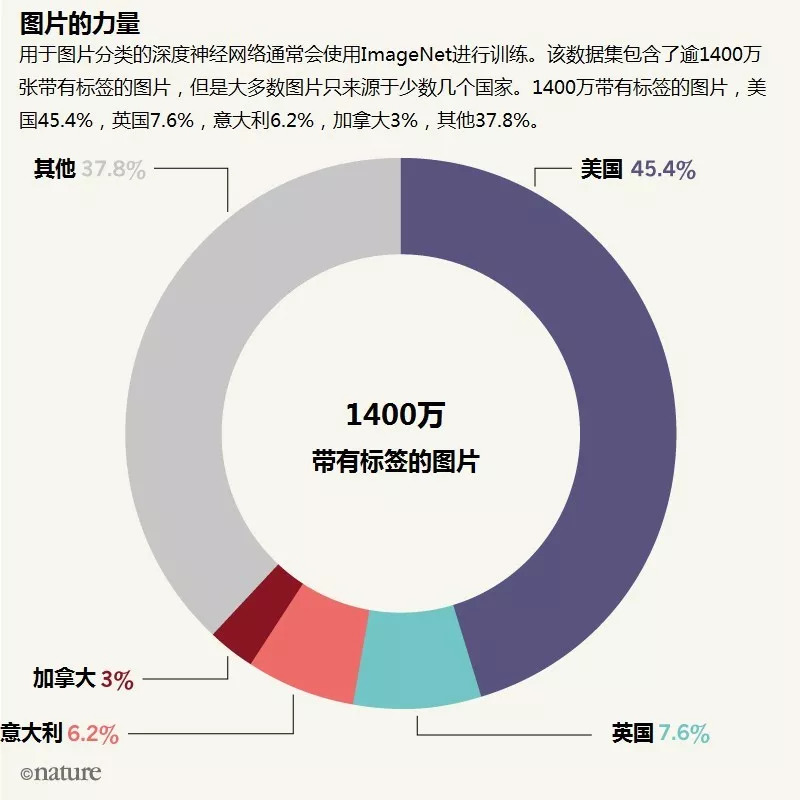
例如,用于图像分类的深度神经网络通常会使用ImageNet进行训练,其中包含了逾1400万张带标签的图片。这种方法会在无意中产生出包含了性别、种族和文化偏见的数据集。

通常来说,会有一些人群被代表过度,而另一些则代表不足。
ImageNet推动了计算机视觉研究,但是其中超过45%的数据来源于美国,而美国人只占世界人口的4%。相反,中国和印度加起来只占其中3%的数据量,而两国人口却占了世界人口的36%。
△图片来源:《自然》杂志
由此看出,这些动物体内除了大脑,还有一个独立的系统来处理身体的变化。这些现象引发了我们的思考:机器人体内可以构建这样的系统吗?答案是——可以。
缺乏地理上的多样性可以在一定程度上解释为什么计算机视觉算法会把传统的身着白色婚纱的美国新娘标注为“新娘”、“礼服”、“女人”、“婚礼”,而印度新娘的照片则会被标注为“表演”和“戏服”。

偏见的另一个来源可以归于算法本身。一个常见的机器学习程序会试图最大化训练数据集的整体预测准确率。
如果训练数据集中某类人群的出现频率远多于另一人群,那么程序就会为占比更多的人群进行优化,这样才可以提高整体的准确率。
有缺陷的算法还会造成恶性循环,使偏见越发严重。举例来说,使用统计方法训练出的系统,例如谷歌翻译,会默认使用男性代词。这是因为英语语料库中男性代词对女性代词的比例为2:1。
更糟糕的是,每次翻译程序默认翻出“他说”,就会提高网络上男性代词的比例——这可能会逆转女性在性别平等上所获得的艰难胜利。
数据偏差来源于制度和社会
数据集中的偏差常常体现出了制度基础和社会权力关系中更深、更隐蔽的不均衡。例如,维基百科看起来是一个丰富多样的数据源,但是该网站上的人物页面里只有18%是女性。
在关于女性的条目中,链接到男性条目的数量远比男性条目链接到女性条目的数量要多,因此搜索引擎里就更容易找到关于男性的条目。女性条目里还包含了更多的伴侣和家人信息。
因此,在构建训练数据集时必须进行技术处理,并将社会因素纳入考虑范围。我们不能局限于方便的分类方式——“女人/男人”,“黑人/白人”等——这些分类方式无法捕捉到性别和种族认同上的复杂性。数据管理者应当尽可能提供与数据相关的描述语的精确定义。

公平是什么?
计算机科学家应努力开发能够稳定应对数据中的人类偏见的算法。
当计算机科学家、伦理学家、社会科学家等人努力提高数据和AI的公平性时,我们所有人都应该思考“公平”到底应该指什么。
数据是应当表现现有的世界,还是应当表现大多数人所追求的世界?
又比如,用来评估应聘者的AI工具是应当评价应聘者是否有能力,还是应聘者是否能融入工作环境?应该让谁来决定哪种“公平”才是更为优先的?
计算机、程序和进程塑造了我们的态度、行为和文化。AI正在改变我们的经济和社会,改变我们交流的方式,改变我们的行政和政治。不平等在我们的社会中积疾已久,不能让AI在不经意间延续甚至恶化这一问题了。
