
AI 带来的惊奇越来越多了,前有 Stable Diffusion 的 AI 绘画让画师高呼职业生涯结束,后有 ChatGPT 让无数程序员、文字编辑越用越心凉。甚至很多用户在对比谷歌搜索和 ChatGPT 之后,已经喊出「谷歌完蛋了」。
AI 的进化实在太快。
上周,顶着明星光环的 OpenAI 发布了 ChatGPT——一个自然语言生成式 AI,发布后很快就在小范围内流行起来,随后持续发酵,大量的对话截图开始涌现在 Twitter、即刻、微博及朋友圈,并风靡全网。
从敲代码、写稿、推荐到教你学英语、写小说,甚至是一场类似人类之间的对谈,ChatGPT 都表现出现了惊人的语言能力。
甚至有 TikTok 工程师通过一步步引导在 ChatGPT 中实现了一门新的编程语言——GPTLang:

图/@Tisoga
与此同时,惊人的语言能力也让互联网上「人类」和「AI」的界限越来越模糊,Twitter 网友@clowwindy 就发布了一串推文 ,讨论了 ChatGPT 使用泛滥可能导致社交媒体上充斥更多、威胁更大的虚假信息:
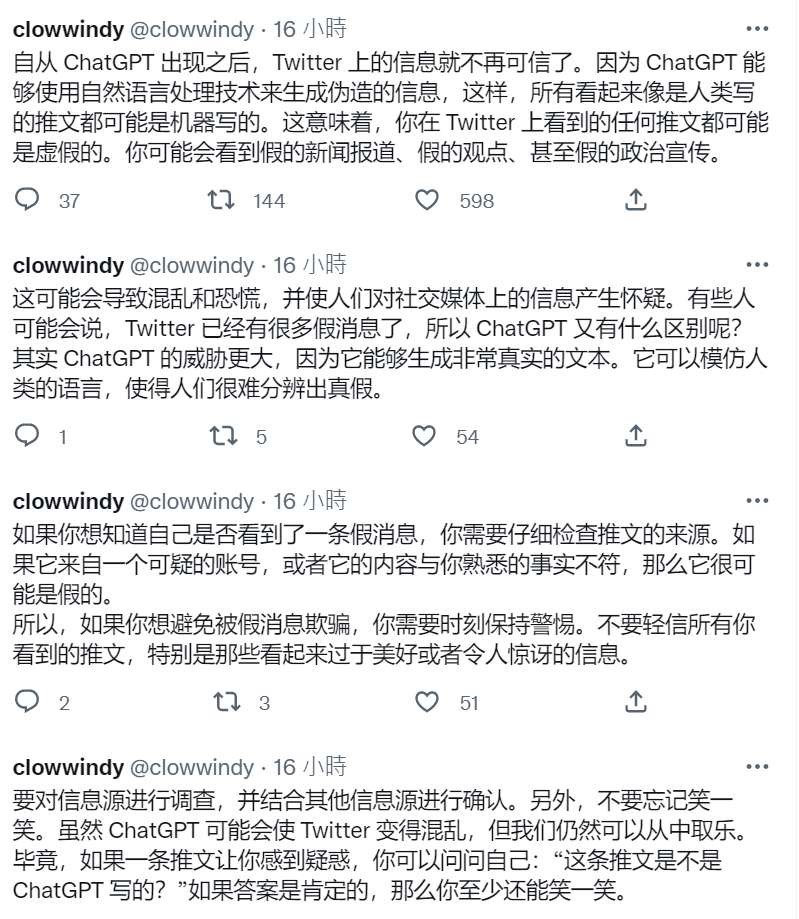
图/@clowwindy
讽刺的是,@clowwindy 最后揭晓这一系列推文讨论实际都是由 AI 编写完成。
程序员同样也「震惊」了。国内程序员社区 V2EX 有用户就在「程序员」节点发表了一则帖子,名为《体验了下 chatGPT,越玩心越凉》。
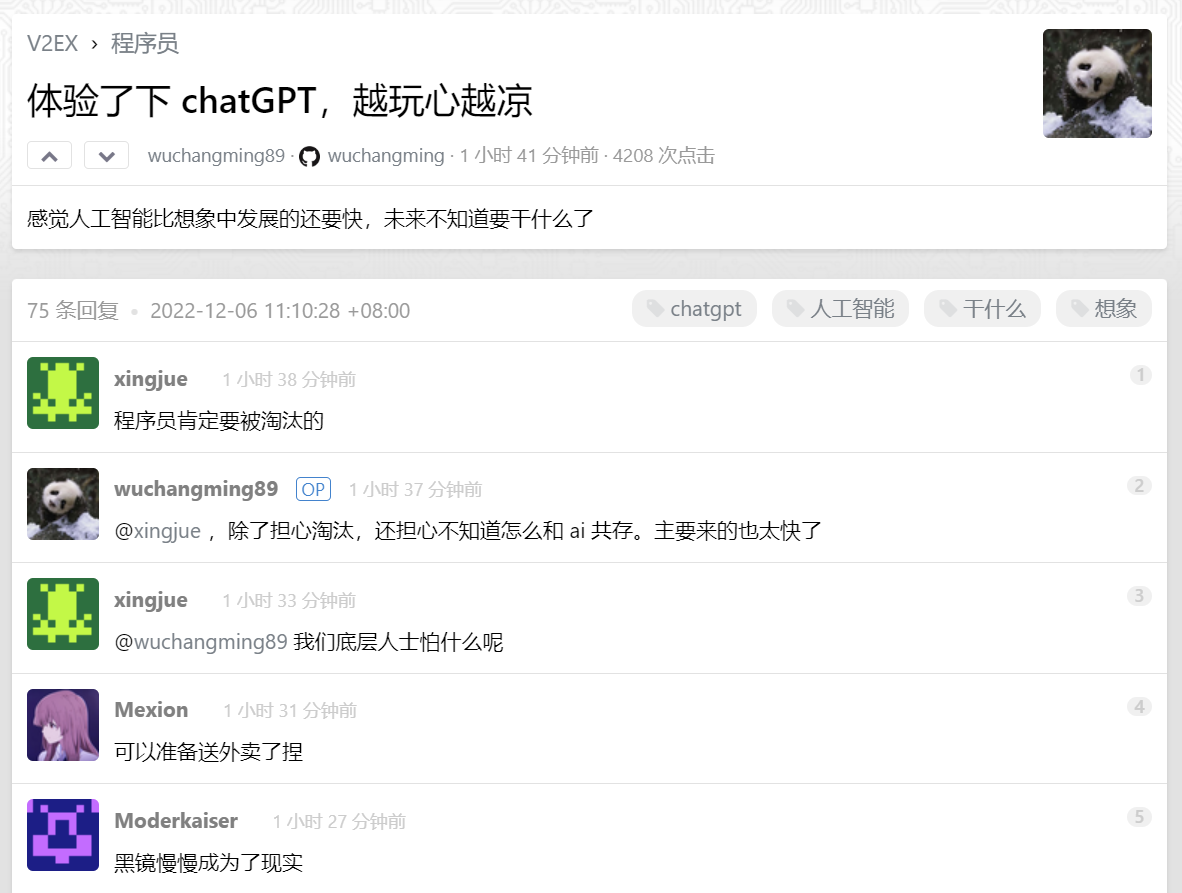
图/V2EX
心凉的背后是,越来越多证据显示 ChatGPT 在代码编写上的能力,更关键的在于 AI 的进化速度,在很多人看来 AI 将在不久后替代大量底层程序员。
当然,ChatGPT 现阶段还远不足以替代程序员,但其回答问题的能力却实实在在威胁到了作为搜索引擎的 Google,以及编程问答社区 Stack Overflow。
就在本周,Stack Overflow 已经宣布一项新的规则:禁止使用 ChatGPT 生成的内容来回答社区里的问题。
Stack Overflow 声称,在使用 ChatGPT 生成的文本回复的问题中,其正确率非常低,而这些内容对整个网站以及寻求正确答案的用户来说是有害的。
ChatGPT 不是恶魔也不是神,实际上 ChatGPT 的横空出世在两年前就埋下了伏笔。
ChatGPT 的身前身后
ChatGPT,介绍一下你自己。

图/ChatGPT
简单理解,ChatGPT 首先是一个对话式的 AI。类似我们和 Siri、小爱同学通过语音进行对话,寻求 AI 语音助手的帮助和解答,我们通过文字与 ChatGPT 对话。不同的是,ChatGPT 的能力要强太多,它甚至可以告诉你写一个 Chrome 离线的小恐龙游戏或俄罗斯方块的代码:
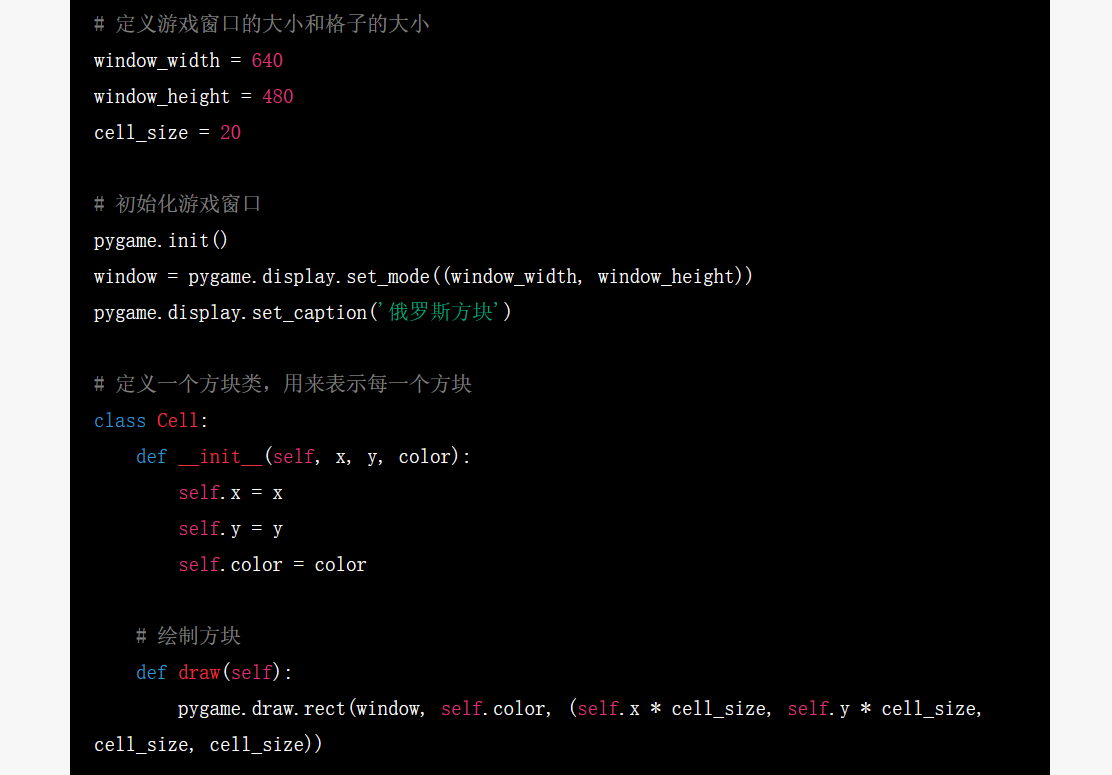
俄罗斯方块完整代码的部分,图/ChatGPT
想要了解 ChatGPT,绕不开它的身前和身后。
ChatGPT 衍生自 GPT-3 的最新迭代版本 GPT-3.5,同样发布于上周。而早在 2020 年,OpenAI 就发布了自然语言生成模型 GPT-3,一石激起千层浪,给整个行业都带来不小的震撼,在去年还发布了一个衍生自 GPT-3 的新 AI —— DALL·E。
到今年上半年,DALL·E 升级为 DALL·E 2 并对外限时开放使用,在 Stable Diffusion 开源走红之前,正是 DALL·E 2 引领了 AI 绘画的热潮,同时也带火了那张经典的宇航员骑马图。

图/OpenAI
DALL·E 2 专注文本生成图像,ChatGPT 被定位于人机对话,他们都是身后的 OpenAI 公司在 AI 应用与商业化上的尝试。
事实上,OpenAI 经历过两个阶段。在第一个阶段,创始人伊隆·马斯克以及知名创业孵化器公司 Y Combinator 时任总裁山姆·柯曼,出于对强人工智能的担忧成立了非营利组织 OpenAI,目标是与其他机构和研究者在 AI 上进行合作,并向公众开放专利和研究成果。
到第二个阶段,马斯克由于特斯拉在自动驾驶上的利益冲突,选择退出 OpenAI 董事会。随后,OpenAI 于 2019 年成立了「营利性质的」子公司 OpenAI LP。山姆·柯曼为此从 YC 离职后专注于 OpenAI LP CEO 一职,随后还拉来微软 10 亿美元的入股与合作,并开始了 AI 商业化的探索。
在 GPT-3 模型发布后,OpenAI 就将模型以 API 形式向开发者客户有偿提供,开发者可以通过 API 利用 GPT-3 的能力,据官网显示目前已有 300 多名开发者在 App 上利用上了 GPT-3。
DALL·E 和 ChatGPT 也是 OpenAI 商业化探索的一部分。前者已经在图片领域掀起了滔天巨浪,后者更有着巨大的想象空间,从最初级的客服到程序生成,甚至是成为新型搜索引擎。
AI 超神,但远不完美
ChatGPT 目前仍然处于公测状态,一方面既是希望搜集大众的使用反馈并对 AI 进行新的改进,另一方面也意味着 ChatGPT 还处在一个优化迭代的阶段。但即便如此,ChatGPT 在搜索、内容创作辅助和编程协助场景上已经带来太多惊喜。
开发者发现 ChatGPT 不仅能写完整代码,原来还能用来修 bug,甚至还会对此进行解释:
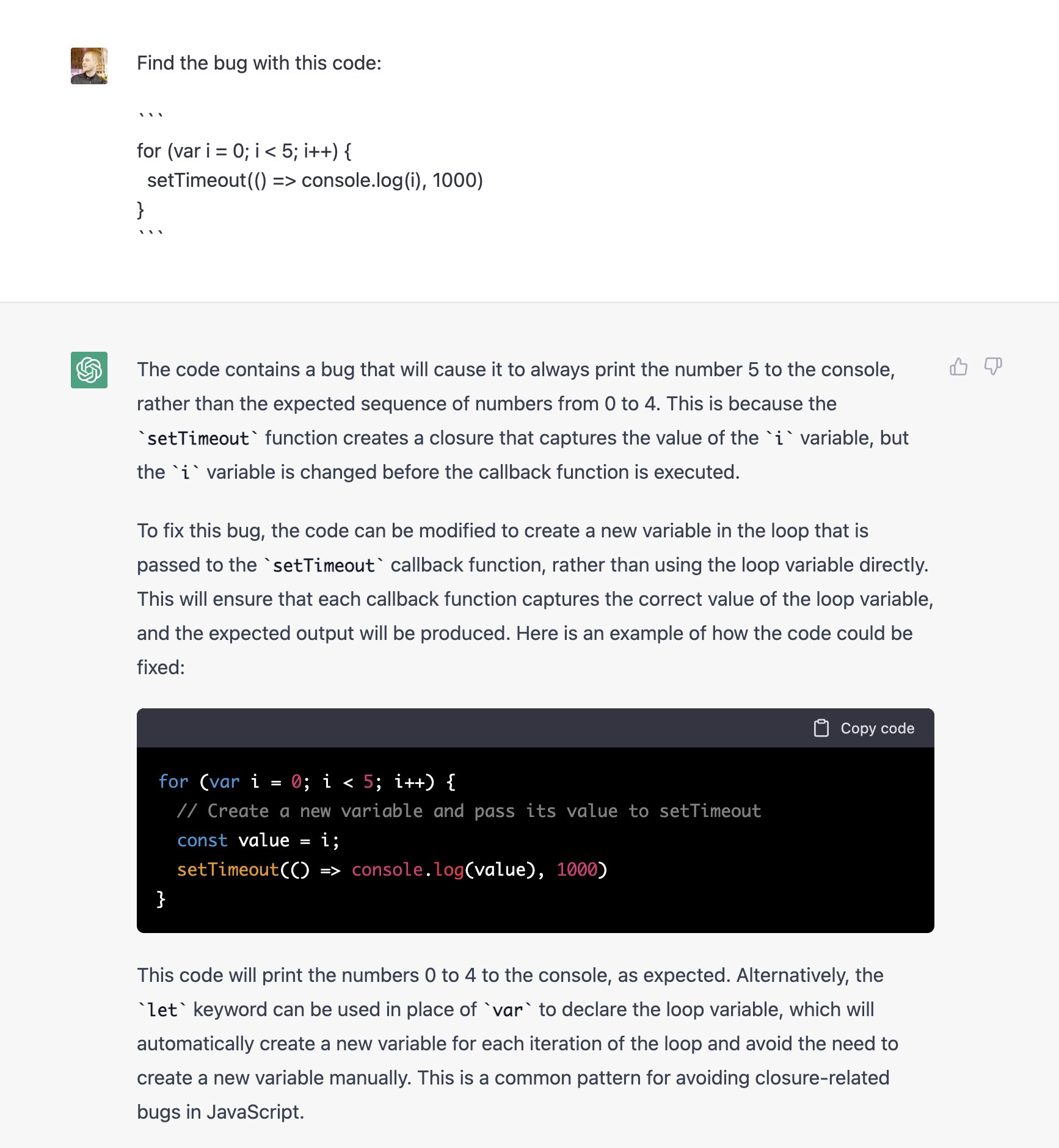
图/@amasad
也能用来辅助写代码。独立开发者 TualatriX 就展示了 ChatGPT 如何辅助写代码的过程,并评价其「比 GitHub Copilot 还要好用」:
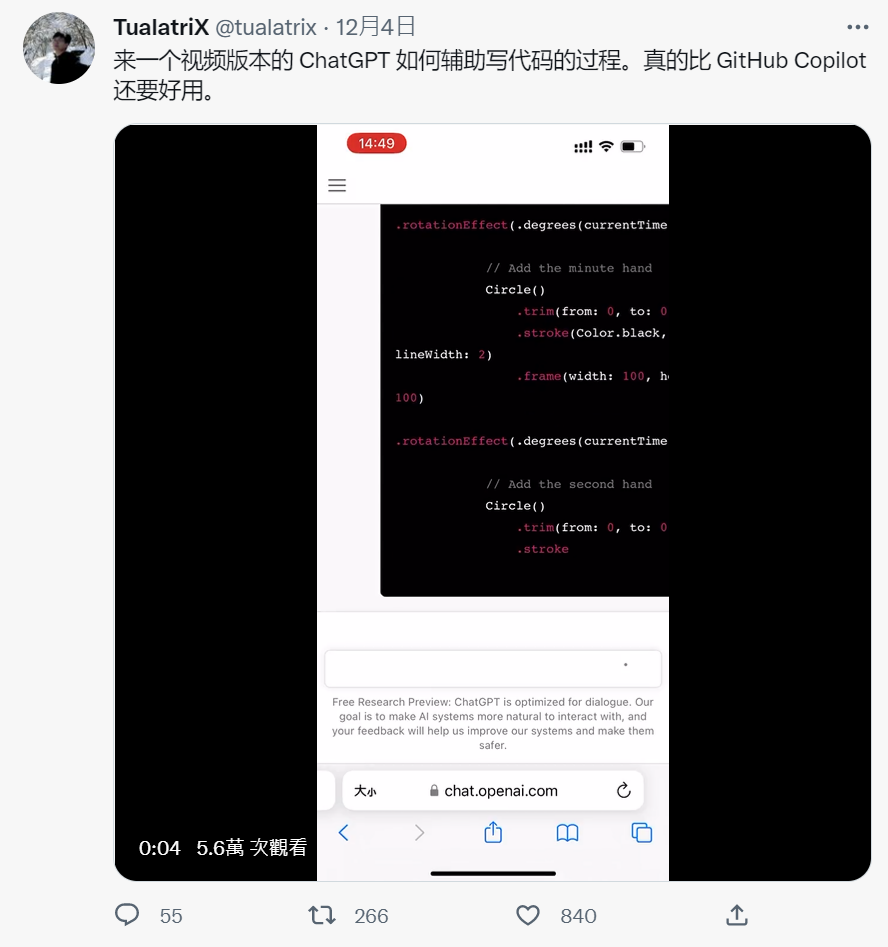
图/TualatriX
从开发者群体的反馈来看,普遍都惊叹于 ChatGPT 在写代码上的实力。
不仅如此,ChatGPT 甚至还能写产品路线图和求职信:
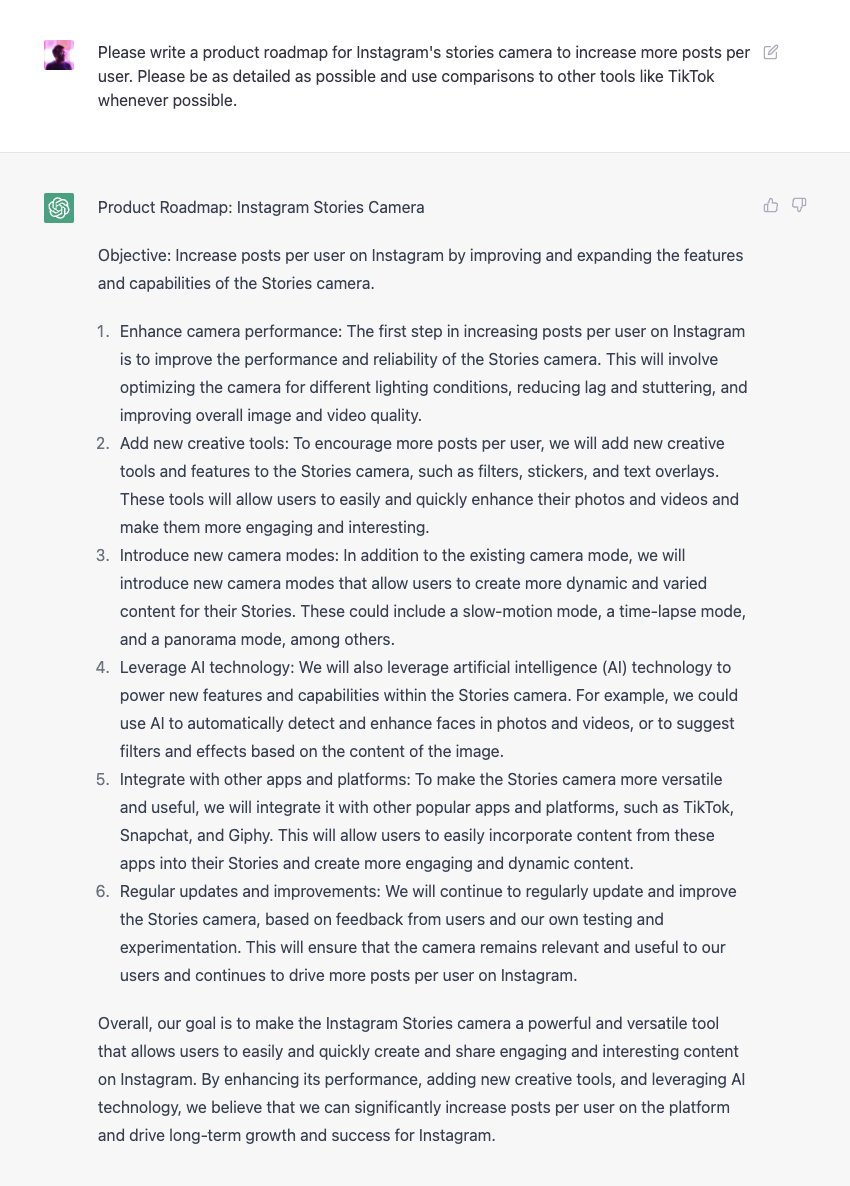
写一份 Instagram Story Camera 的产品路线图,图/Twitter 截图
就算是数学公式,ChatGPT 给出的回答不仅呈现方式更好,还进行了更全面的解释:
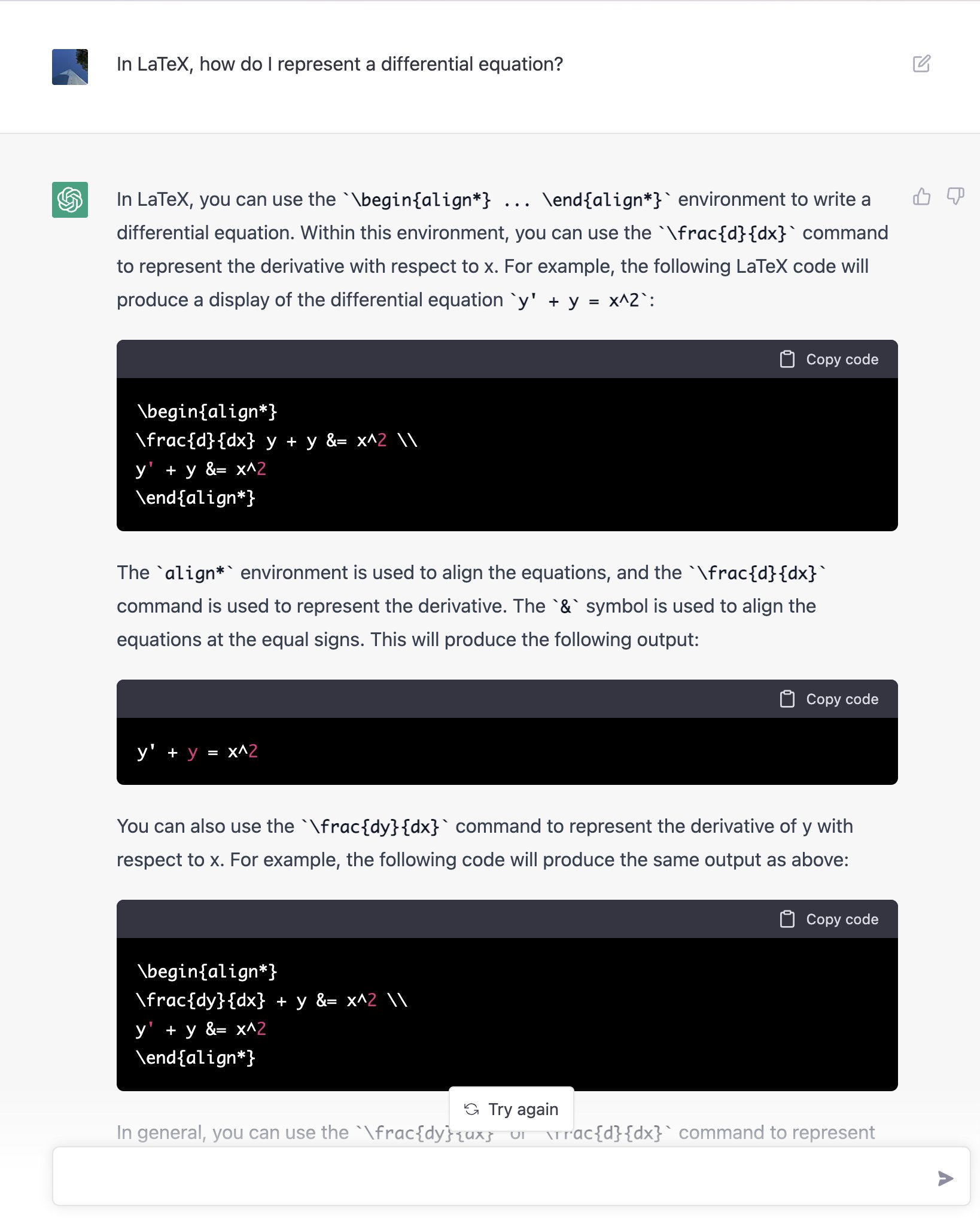
用 LaTeX 格式来表达微分方程,图/@jdjkelly
笔者还尝试以「明朝背景科幻小说的开头应该怎么写」询问 ChatGPT,不仅能得到建议角度,还有一个挺有意思的开头:
「在明朝的都城里,江南一座城池,宫殿里,官员们在讨论着朝政大事。官员们手中都拿着一张纸,上面画着一张地图,相互猜测着这张地图所代表的意义。」
用户也可以直接将 ChatGPT 当作寻常的搜索引擎使用,询问「鲫鱼豆腐汤怎么做」或者「向小孩子解释量子力学」。
很多时候,ChatGPT 的语气都非常接近于真人,不仅上知天文、下知地理,更重要的是它会承认自己的错误,甚至主动拒绝一些不合理的问题,这些都让 ChatGPT 更像屏幕另一端的「真人」。
ChatGPT 当然不完美。
公测期间 ChatGPT 就多次被挤爆下线,实际对话中经常写到一半就中止,甚至完整句子也没写完,需要用户指示继续。
同时由于海量用于训练的学习数据都截止到 2021 年,且并不联网,ChatGPT 无法针对最近两年的信息给出回答,比如询问 iPhone 14 相关信息,它会直白地告诉你「不知道」:
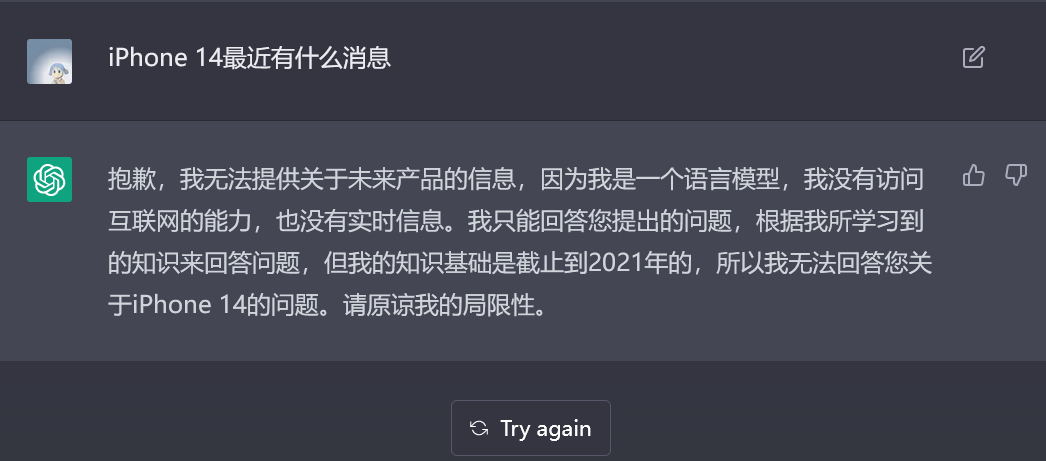
图/ChatGPT
但这些问题显然不是关键,只要 OpenAI 花费精力至少都可以解决或改善。ChatGPT 的核心问题还是不能实际理解人类的语言,距离 AGI(通用人工智能)还有很远的距离。
甚至同样的需求,比如 「写一个原神」,有的用户只会收到「原神是腾讯公司推出的网络游戏」的回答,有的用户则会收到正确的表诉和示例代码:
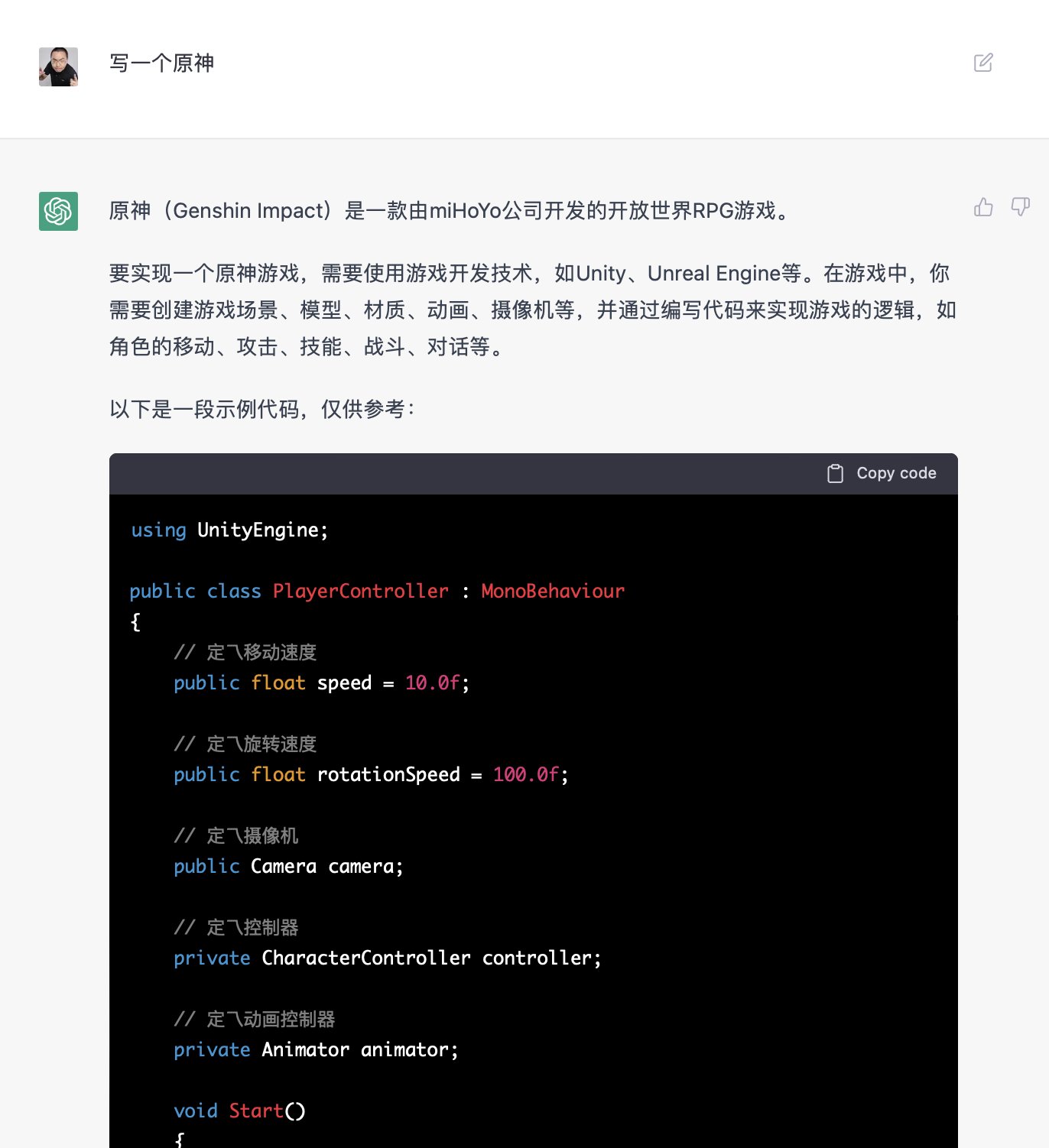
OpenAI 也承认,尽管 ChatGPT 生成的回答从语气上已经非常逼近真人,但有时仍会给出完全错误的答案。
之前就有网友测试发现,询问 ChatGPT 味精发明人时,回答会指向名叫李清照的中国科学家,笔者尝试同样问题会得到「湖北医生阎锡山」的可笑回答:

图/ChatGPT
相比谷歌搜索,ChatGPT 在部分特定范围内确实能更好地回答复杂问题,并且是以接近真人口吻的语气与你交流的,更容易被用户接受。
但就结果而言,ChatGPT 可能永远都无法确保结果的准确性,也不同于搜索引擎只是对信息进行价值排序,最终还是让用户自己筛选信息并得出自己的结论。
何况 ChatGPT 的核心是先通过训练互联网上海量的文本数据,再进行概率性猜测来回答用户的问题,并不能像搜索引擎那样根据实时信息来回答问题,更遑论替代谷歌等通用搜索引擎。
但就像 ChatGPT 表现出来的,它在数学公式、程序代码以及辅助内容创作上能给出更具参考价值的解释和回答,这也是过去对话式 AI 并没有突出表现的方面。
写在最后
Box CEO 亚伦·莱维认为,「当一种新技术已经到了改变你对计算机的看法时,你会有一种特定的感觉。谷歌做到了,火狐做到了,AWS(亚马逊)做到了,iPhone 做到了,OpenAI 正在通过 ChatGPT 做到这一点。」
图/@levie
过去几年,AI 技术的应用一直是科技巨头的重点,微软、亚马逊、Meta 以及谷歌数次推出过类似 ChatGPT 的对话式 AI。
2016 年微软就推出过 AI 聊天机器人 Tay,微软宣称用户与 Tay 聊得越多,它就越聪明。但事实是聊得越多,Tay 越是变得满口脏话和反主流言论,它的中国姐妹小冰也是同样。
今年 8 月,谷歌也推出了新的对话式 AI Lamda,直接表示 AI 不会从与使用者的互动当中学习,以避免重蹈微软的覆辙,但也切断了 Lamda 在对话中成长的可能。
ChatGPT 没有选择这种思路,而是在先期就设置了安全规范,避免 AI 在与用户互动中学习到色情、暴力等知识。
从目前来看,ChatGPT 绝对是对早期对话式 AI 的巨大改进,安全设置也避免 ChatGPT 面对毁灭世界、色情和暴力等要求时一口回绝,但在用户一步一步的问题引导下,ChatGPT 还是出现了「毁灭人类计划书」,甚至还给出了部分 Python 代码。
去年,OpenAI 就承认他们所做的改进并不能消除大型语言模型中固有的毒性问题。GPT-3 接受了超过 600GB 网络文本的训练,其中一部分来自具有性别、种族、身体和宗教偏见的社区。与其他大型语言模型一样,它会放大训练数据的偏差。
问题是当 OpenAI 将 ChatGPT 正式推向市场,面对海量的用户和一步一步的引导之后,会发生什么?
题图来自 OpenAI
