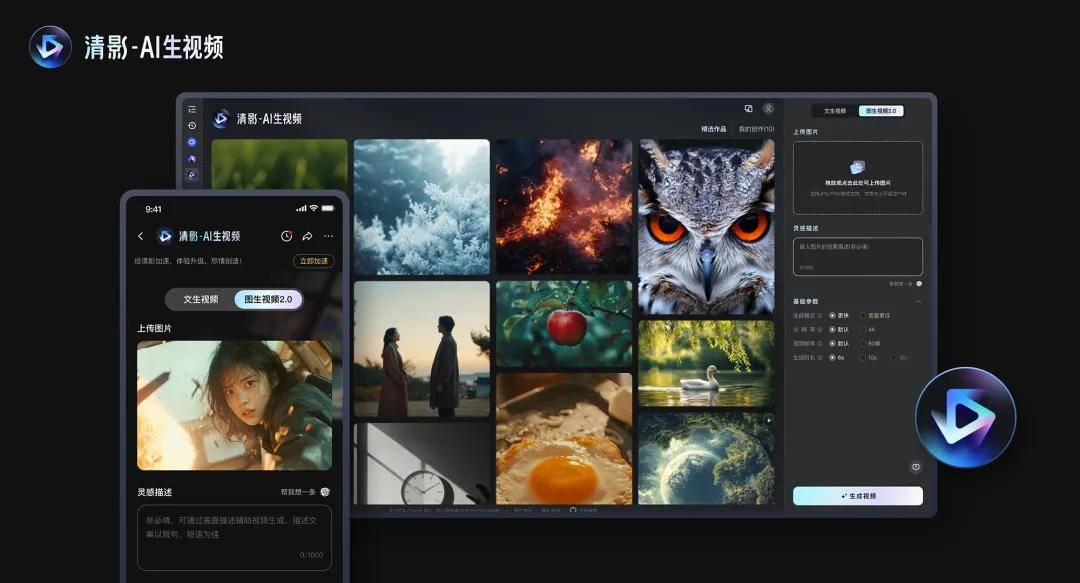
就在刚刚,智谱清言App上线了“新清影”,同时对外开源了智谱最新的图生视频模型CogVideoX v1.5。
3个多月前的智谱Open Day上,视频创作智能体清影正式在智谱清言上线,只需30秒即可生成时长6秒、1440×960清晰度的高精视频,随即涌现出了短视频、表情包梗图、广告制作等创新玩法。
短短一个多月的时间,智谱就将清影背后的图生视频模型CogVideoX 2B和5B版本给开源了,可以在消费级显卡上流畅运行,陆续衍生出了CogVideoX-factory等大量二次开发项目。
经过3个多月打磨和进化的“新清影”,都有什么能力上的提升,又将带来哪些有趣的新体验呢?
我们有幸拿到了提前内测的资格,下面和大家一起来揭晓答案。
01 更高清、更快速、更逼真的图生视频
在和多位内容创作者的沟通中,我们了解到:相较于文生视频的趣味性,大家对图生视频有着更高频的需求,因为图生视频进一步提高了生成视频的控制和一致性,可以快速生成可用的视频素材。
“新清影”的第一个亮点,正是“图生视频”能力的全面提升,确切地说可以归纳为四个方面:
一是4K超高清分辨率,相较于清影6秒、1440×960的清晰度,“新清影”支持生成10s、4K、60帧超高清视频。
二是可变比例,用户可以上传任意比例的图像生成视频,哪怕是超宽画幅,都可以生成对应比例的视频。
三是多通道生成能力,以往的图生视频类产品,一次只能生成一个,“新清影”可以一次性生成4个视频。
四是模型能力的提升,CogVideoX在内容连贯性、可控性和训练效率等方面实现了多项创新,让“新清影”的图像质量、美学表现、运动合理性、复杂提示词的语义理解等能力显著提升;同时有着更强的人物面部、表演细节、动作连贯性和物理特性模拟。简而言之就是更加自然和逼真。
前三个方面的提升很容易判断,需要验证的创新点恰恰是视频质量和逼真度,也是视频生成类产品最核心的价值。于是我们找到了几组图片,输入对应的提示词,来验证“新清影”是否言过其实。
第一组照片是站在木桩上的仓鸮,后面的背景被虚化了,给出的提示词也很简单——“让图片中的动物动起来”,以此来验证“新清影”在运动合理性、动作连贯性和图像质量等方面的表现。
视频的整体表现可圈可点,仓鸮转头的动作自然连贯,每一根毛发、每一道纹路、每一处细节都清晰可见。即使背景做了虚化处理,也能感受到有风吹动树叶,仓鸮脚上的绑带也在随风晃动,近乎可以充当真实拍摄的视频。
第二组是一张在雪地里行驶的汽车,在构图上比前面要复杂的多,主体是一台黑色汽车,远处隐约可见一片森林,同时在提示词上也更复杂一些——“在雪地里弹射起步的汽车,掀起了滚滚烟尘”。
这次生成的视频超出了我们的预期:尽管汽车有一点点形变,但起步时轮胎转动溅起的残雪、汽车起步的速度、汽车驶远后逐渐消失的烟尘等等,都遵循了物理规律,甚至可以清晰的看到远处被汽车遮挡的树木,并且符合冬天的场景。
做一个总结的话,“新清影”生成的视频在画面上高度还原了输入图像,光影和色调自然地融入了场景中,视频的自然度和逼真度极大提升。更重要的是,视频生成不再需要不停“抽卡”和二次剪辑,生成的素材几乎可以直接使用。
02 “无声视频”一步跨越到“有声时代”
“新清影”的另一大亮点,在于即将上线的音效功能。
目前AI生成的视频还处于“默片”时代,抑或是人为添加一段背景音乐,并没有解决音效问题。“新清影”即将填补市场空白,可自动生成与画面匹配的音效,让AI视频一步跨越到了“有声时代”。
为了验证音效功能的效果,我们从Pixabay上下载了三段无声的视频片段,然后用智谱的音效模型CogSound匹配了音效。
第一个片段是田野中工作的收割机,并不是一个常见的场景,但CogSound准确生成了拖拉机轰隆隆的引擎声,音效和画面的连贯性、平滑过渡完成地很好,让人仿佛置身于秋收的热闹场景里。
第二个片段是篝火旁倒水的场景,CogSound的表现再次令人惊艳,一开始是木柴燃烧的噼啪声响,在水倒出的时候,恰如其分地出现了倒水的声音,声音和画面几乎没有任何偏差和失配。
第三个片段是大雪中站在木桩上的鸟,也是一个语义理解的“陷阱”,很可能会出现音效的错配,譬如森林里的鸟鸣声。结果超出了我们的想象,可以听到风雪天熟悉的“白噪音”,并且伴随着嘈杂的鸟叫。
如果说“新清影”的图生视频能力,解决了内容创作中对高质量素材的需求,音效功能上线后,进一步让外界看到了更大的应用空间。
比如电影中大规模战斗、灾难等场景,现在可以直接用AI生成音效,不仅将缩短制作周期,还将极大地降低制作成本,在提升产能和效率的同时,加速电影制作从流水线时代进入到智能化时代。
再比如游戏、广告等内容的音效制作,过去需要专业的技术团队,利用专业的设备才能完成,现在只需要一个音效模型CogSound。创作门槛的降低,对一个行业繁荣度的催化作用不言而喻。
可能很多人会产生这样的疑问:既然音效制作是一个复杂的系统性工程,CogSound是怎么实现的?
这里就涉及到大模型中常用的Diffusion架构。
核心思想是将扩散过程从高维原始音频空间转移到低维潜空间中进行,可以在保持生成质量的同时,实现高效的音频合成。
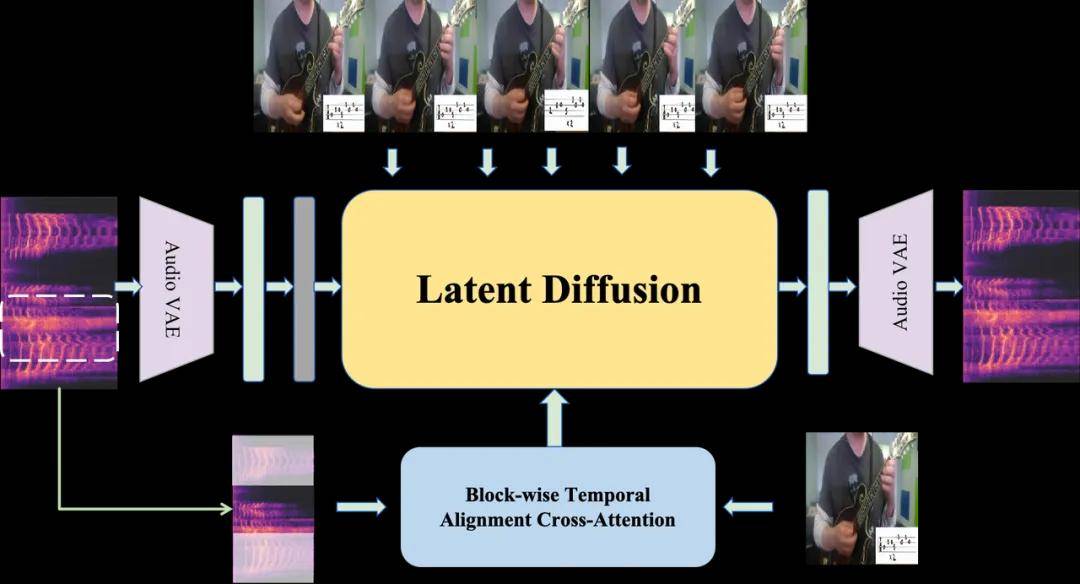
智谱的研发团队采用了基于Unet的Latent Diffusion潜空间扩散,同时引入分块时序对齐交叉注意力机制,在架构中整合了旋转位置编码技术,确保了生成音效与视频内容在语义上的高度一致,并在连贯性和平滑过渡方面效果显著。
通俗一些的解释,智谱的CogSound是这样工作的:
先基于GLM-4V的视频理解能力,准确识别并理解视频背后的语义和情感,再由音频模型根据视频内容生成音效、节奏,甚至是复杂的混合音效,包括爆炸声、水流、乐器、动物叫声、交通工具的声音等等。
03 内容创作“All in One”已不再遥远
年初视频生成模型刚诞生时,吸引了无数人的兴趣,其中畅想最多的一个方向,正是越来越多人参与到视频内容的生产创作。
可惜到目前为止,大多数产品还只是生成短小片段的“创意玩具”,在社交平台上进行轻量化的应用,和生产力仍然有相当大的距离:需要花费大量的时间进行视频剪辑和合成,才能制作出一个看起来还行的短视频。
对于其中存在的症结,可以大致分为两个方面:
一个是模型本身的能力局限,比如语义理解能力,能否准确理解用户的指令;视频生成效果,涉及画面流畅度、人物稳定性、动作连贯性、光影一致性、风格准确性等等;以及生成视频的时长和分辨率。
另一个是产品的易用性,相较于PR、AE等专业的制作工具,AI生成视频极大地降低了门槛,只需输入简短的指令,即可实现丰富的效果。但距离普通小白快速生成高质量视频,还有很长一段路要走。
乐观的是,技术的每一次迭代,都让理想离用户更近一步。
以智谱为例,不到一年时间里,就在视频时长、生成速度、分辨率、一致性等方面实现了长足的进步,验证了scaling law在视频生成方面的有效性,不排除模型能力在很短时间里再一次创新升级的可能。

毕竟3个多月前的清影,还是国内最早全量上线 C 端、人人可用的生成视频功能,刚刚实现技术的从0到1,仅一个季度就完成了能力的全面升级。在这个“技术大爆炸”的时代,所有的技术难题,在根结上不过是时间早晚的问题。
而在产品易用性上,也传出了一些利好的“小道消息”。
联想到智谱在半个月前上线的情感语音模型GLM-4-Voice,和“新清影”一同亮相的音效模型CogSound、音乐模型CogMusic,已然构建了基于 GLM 原创可控技术的,覆盖文本、图像、视频和声音的多模态模型矩阵。
于是我们进行了进一步的测试:让“新清影”将图片生成视频,同时用CogSound给视频生成对应的音效。
除了效果依旧让人惊艳,更直观的体验是效率,整个过程只有几分钟的时间。可以预见,将照片素材批量生成自带音效的视频,或是接下来一段时间里一个重要的应用方向。
进一步猜测:是否存在用工具流同步调用多个模型,只需一个指令就能生成画面和音效同步的视频呢?
借用智谱官方的表态来看:“我们的理想状态是,只需一个好的创意,剩下的事AI都能辅助搞定,轻松将一个 idea、一张图,变成一段自带 bgm 的影片。”言外之意,从脚本、视频画面到声音和音效,过去需要整个团队分工协作完成的任务,以后都可以交给大模型,实现全流程自动化。
一个All in One的视频创作平台,注定不再遥远。
04 写在最后
也许过不了多久,短视频的创作模式就将被重构。
创作者们不再需要亲自出镜,不再需要奔赴拍摄地点;只要通过语言清晰描述自己所需的场景与内容,就可以轻松批量生成符合需求的短视频。
内容创作不再拘泥于专业群体,普通用户也可以通过简单、直观的工具,用AI视频表达自己的创意和想法。
这是大模型的机会,也是所有创作者的机会。
